Embeddings
Embeddings are numerical representations of machine learning features used as input to deep learning models. One-hot encoding, TF-IDF and PCA were early ways of compressing large amounts of textual data. Word2Vec was first step forward in moving on from simple statistical representations to semantic meaning of words. Transformers, transfer learning, generative methods etc. have all contributed to the explosion in use of embeddings and establishing them as a foundational ML data structure.
Most of the notes here are a summary of the embeddings paper by Vicki Boykis. Embeddings are compressed context-specific representations of content.
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
Embeddings are deep learning models’ internal representations of their input data. To build powerful DL models, companies collect and feed 100s of millions of TBs of multimodal data to these models. They are now a critical component of ML systems. They are used for user consumption recommendations, but also at places like Netflix, to make content decisions based on user preference popularity.
When it comes to text data, word embeddings capture the context of the paragraph or previous sentences along with capturing the semantic and syntactic properties and similarities of the same.
What does embedding (the verb) do?
- Transforms multimodal input into representations that are easier to perform intensive computation on, in the form of vectors, tensors, or graphs.
- Compresses input information for use in machine learning task
- Creates an embedding space that is specific to the data the embeddings were trained on but that, in the case of deep learning representations, can also generalize to other tasks and domains through transfer learning — the ability to switch contexts — which is one of the reasons embeddings have exploded in popularity across machine learning applications
Raw input data is passed into an ML model that compress the multidimensional input data by compressing it into a lower-dimensional space. The result, a set of vectors, is called the embedding space.
 For most ML problems, anything beyond 200-300 dimensions has diminishing returns.
For most ML problems, anything beyond 200-300 dimensions has diminishing returns.
Once a multi-dimensional embedded representation of a word, sentence or image is created, the possibilities are endless. For e.g., a mathematical nearness (cosine similarity) score of two embeddings are highly useful in content understanding, search etc.
Embeddings are probably most useful when it comes to surfacing information that is relevant, i.e. an item that is of interest to the user. This is important in content recommendations, purchase recommendations and information retrieval platforms like search engines.
Flutter
Let’s continue the study of embeddings in the context of building an imaginary social media app called Flutter, with a feed for users to consume content through - has posts from followers, recommendations based on topics of interest, recommendations based on user behavior, advertised posts etc.
Recommender systems are systems set up for information retrieval, a field closely related to NLP that’s focused on finding relevant in- formation in large collections of documents. The goal of information retrieval is to synthesize large collections of unstructured text documents. Within information retrieval, there are two complementary solutions in how we can offer users the correct content in our app: search, and recommendations.
- Search: directed information seeking. User has a specific query, and would get a list of refined results
- Recommendation: We don’t know what the user is looking for exactly, but we would like to infer and recommend based on their learned tastes and preferences.
Problem
Will a particular flutter user continue with the app? It’s a classic ML problem of predicting a user’s likelihood of churn using meta features like time_since_previous_post, posts_in_last_4_weeks, engament_metric, age, geographic_location etc.
All ML models expect features to be a numeric value since they converge (minimize loss function) through matrix multiplications. To enable that, we use embeddings to transform textual information such as geographic_location into a vector representation (i.e. an embedding).
for e.g., “US” = [10, 6, 7] “UK” = [8, 3, 4], etc.
Words to vectors Fundamental concepts:
- Encoding: convert non-numerical multi-modal (text, image, combinations of both) into numbers.
- Vectors: encodings are stored as vectors, to allow for mathematical operations in an optimized way
- Lookup matrices: lookup tables, hash tables, attention are the same things that help us map between words and the numbers.
In recommendation systems, in the context of Flutter, rows are the individual data about each user, and column data represents the given data about each post. If we can factor this matrix, that is decompose it into two matrices (Q and PT) that, when multiplied, the product is our original matrix (R), we can learn the “latent factors” or features that allow us to group similar users and items together to recommend them.
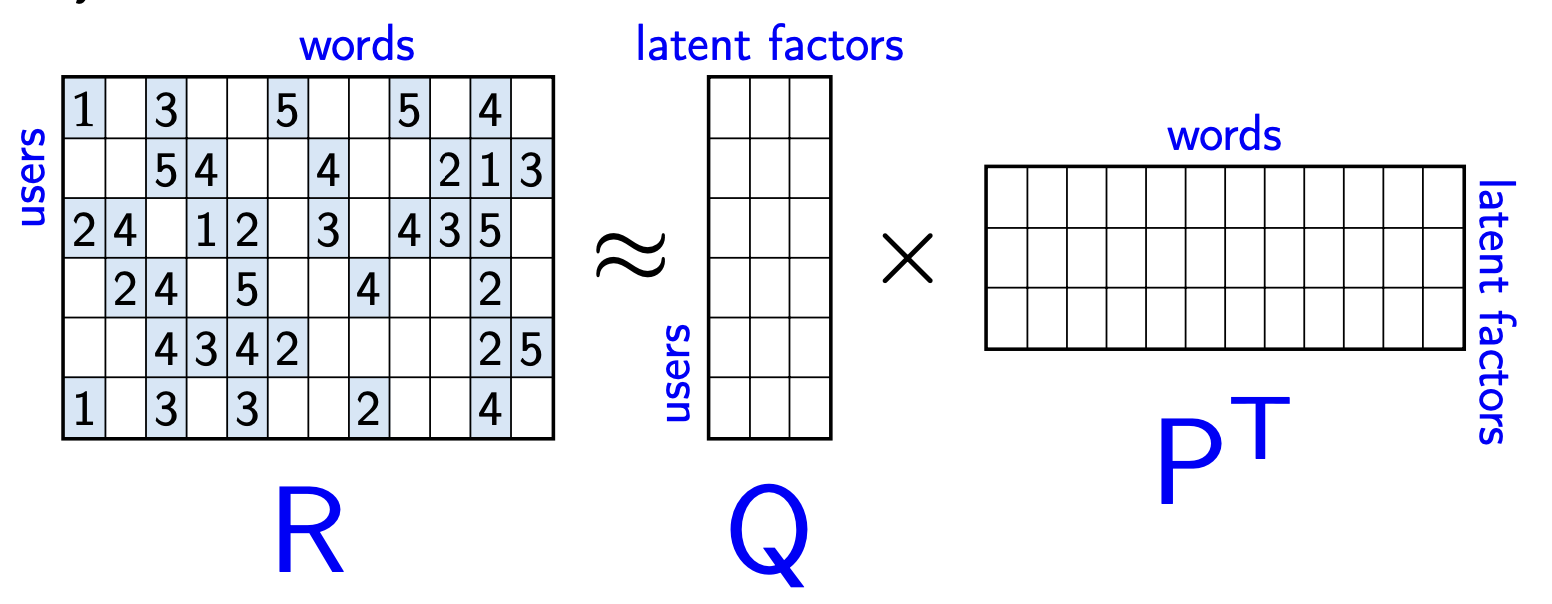 Here, the matrix R has the count of each word in all of the users’ posts. Considering the vocabulary of the entire english language is likely to be represented by “words” here, it’s obvious this is going to be a really sparse vector.
Here, the matrix R has the count of each word in all of the users’ posts. Considering the vocabulary of the entire english language is likely to be represented by “words” here, it’s obvious this is going to be a really sparse vector.
One-hot encoding, TF-IDF, SVD, LSA, LDA etc. are some of the earlier approaches to embedding that focused on generating sparse vectors that can given an indication that words are related, but they couldn’t identify semantic relationship between them. For example, “The dog chased the cat” and “the cat chased the dog” would have the same distance (i.e. cosine similarity) in the vector space, even though they’re two completely different sentences.
Word2Vec is an elegant solution to this problem and it uses neural networks. It is a family of models that has several implementations, each of which focus on transforming the entire input dataset into vector representations and, more importantly, focusing not only on the inherent labels of individual words, but on the relationship between those representations. The end-goal of the Word2Vec models is to learn the parameters that maximize that probability of a given word or group of words being an accurate prediction.
Let’s learn the CBOW method of building these embeddings.
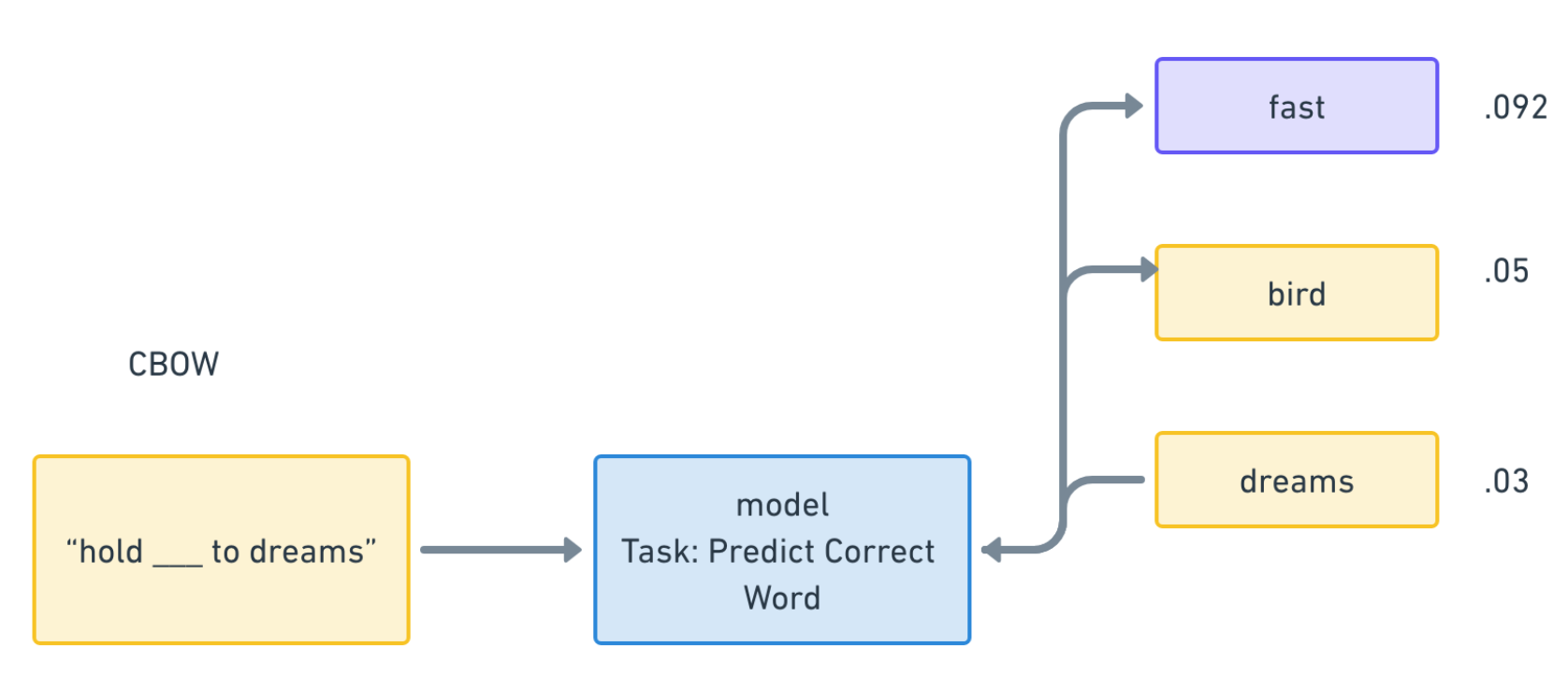
Here, we remove a word from the middle of a phrase (known as the context window), and train the model to predict the probability that a given word fills the blank. If we maximize the probability that the word belongs in the sentences, we’ll learn good embeddings for our input corpus (i.e. the list of all sentences / posts that is collected to train).
In Flutter app’s case, our corpus is the list of all the posts we’ve collected.
For e.g.
corpus = [“Hold fast to dreams, for if dreams die, life is a broken-winged bird that cannot fly.”, “No bird soars too high if he soars with his own wings.”, “A bird does not sing because it has an answer, it sings because it has a song.”]
- To prepare the data to train a Word2Vec model, the corpus is first tokenized - smaller word-level representation of each sentence - for processing.
- Next step is to create one-hot encodings of each word to a numerical position, and each position back to a word, so that both words and vectors are reasily referenced. The goal is to be able to map back and forth for lookups and retrievals.
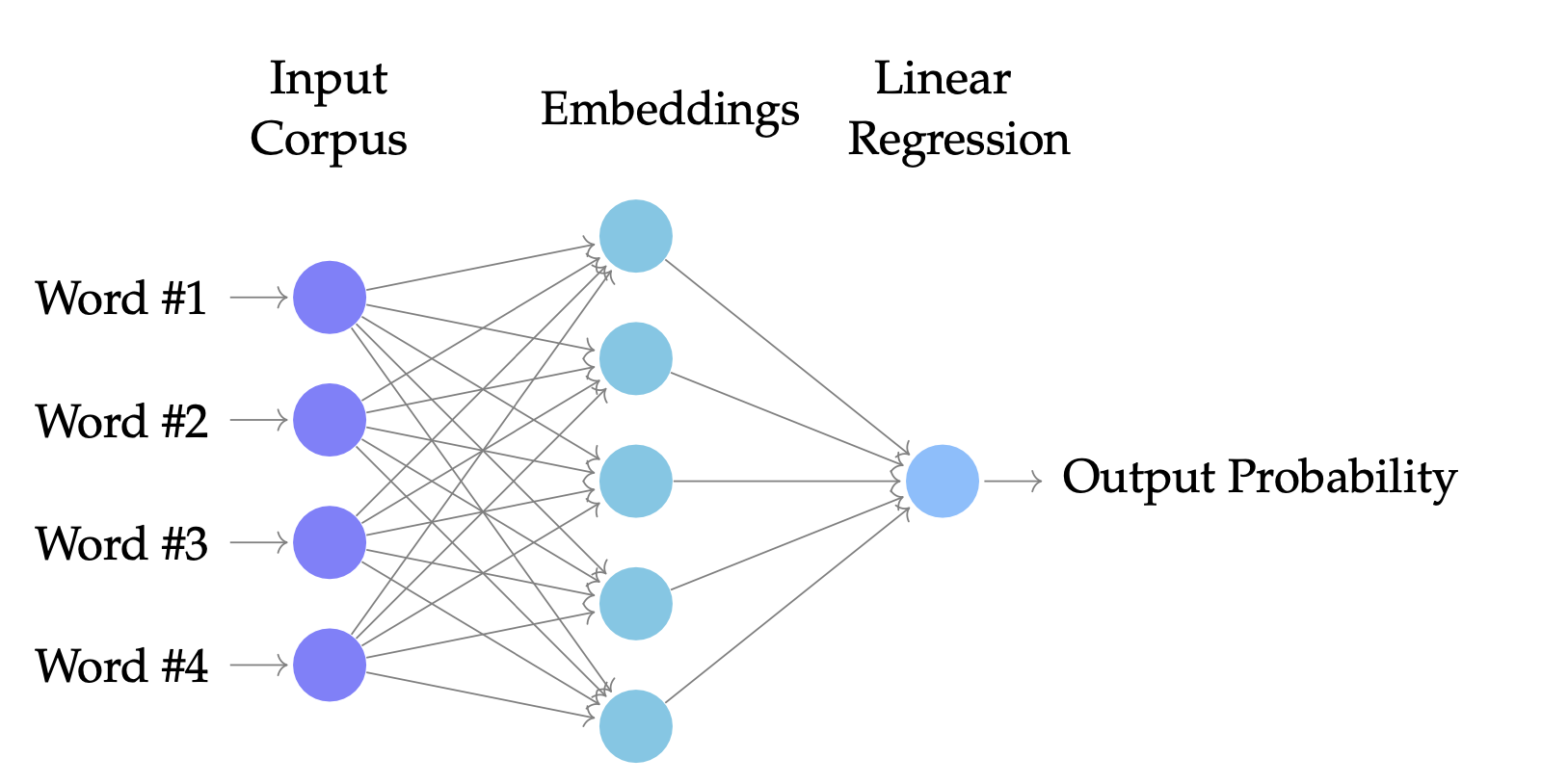
- This occurs in the Embedding layer. It is like a one-hot encoded matrix, and allows lookups.
- In this embedding layer, called Word2Vec, each value in the vector represents the word on a specific dimension, and more importantly, unlike many of the other methods, the value of each vector is in direct relationship to the other words in the input dataset.
- Next, a single word is taken along with a sliding window of say 2 words on both sides. This word is then tried to be inferred. This is also known as context vector or attention.
- A neural network, like the one above, is then trained to find the right model weights under which the right word is predicted given its context window.
- The normal neural network processes - batching, loss (difference between the real and predicted words) minimization, backpropagation etc. are followed to get the right model weights.
- Once an iteration through the training set is completed, it creates a model that retrieves both the probability of a given word being the correct word, and the entire embedding space for the vocabulary.
Context Window: In the sentence “No bird [blank] too high”, the model is built to predict the answer “soars” and the context window is the two words preceding - “No bird” and the two words succeeding “too high” together form the context window.
In a nutshell, word embeddings can be defined as a dense representation of words in the form of vectors in low-dimensional space. These embeddings are accompanied by learnable vectors, or parameterized functions. They update themselves during backpropagation using a loss function, and try to find a good relationship between words, preserving both semantic and synaptic properties.